大模型
视觉模型
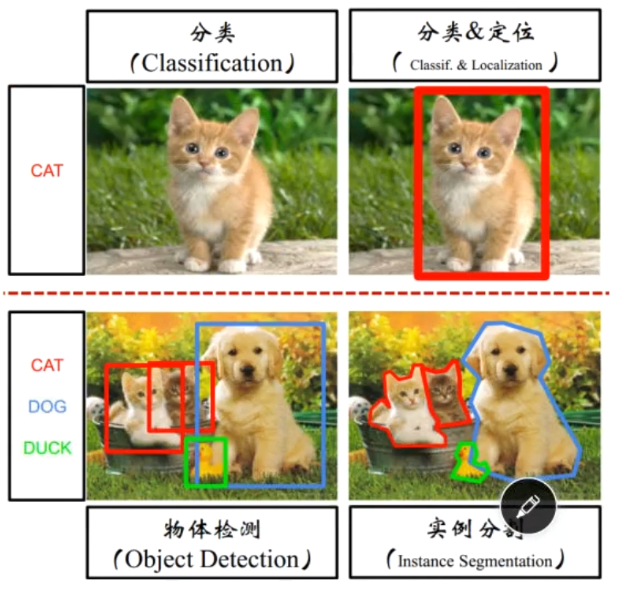
分类
任务
图像分类:识别出图中出现的物体类别是什么,其功能主要是用于判断是什么?
- VGG
- GoogleNet
- ResNet
图像定位:不仅仅需要识别出是什么物体(即分类)同时需要预测物体的位置信息,也就是单个目标在哪里?是什么?
- RCNN
- Fast RCNN
- Faster RCNN
目标检测:多目标的定位,即在一个图片中定位多个目标物体,包括分类和定位,也就是多个目标分别在哪里?分别属于那个类别?
- RCNN
- Fast RNN
- Faster RCNN
- SSD
- YOLO
模型架构
- 二阶段:R-CNN、Fast R-CNN、Faster-R-CNN、SPP-Net、R-FCN
- 一阶段:YOLO、SSD、FPN
图像分割与目标检测:Cascade R-CNN
参数介绍
IOU
两个边界框(bounding box)的重叠度
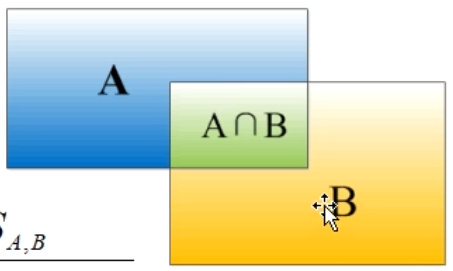 $$ IOU=\frac{A\cap B}{A\cup B}=\frac{S_{_{A,B}}}{S_{_A}+S_{_B}-S_{_{A,B}}} $$
$$ IOU=\frac{A\cap B}{A\cup B}=\frac{S_{_{A,B}}}{S_{_A}+S_{_B}-S_{_{A,B}}} $$ MAP
精度和召回率
| 正例(实际) | 负例(实际) | |
|---|---|---|
| 正例(预测) | TP | FP |
| 负例(预测) | FN | TN |
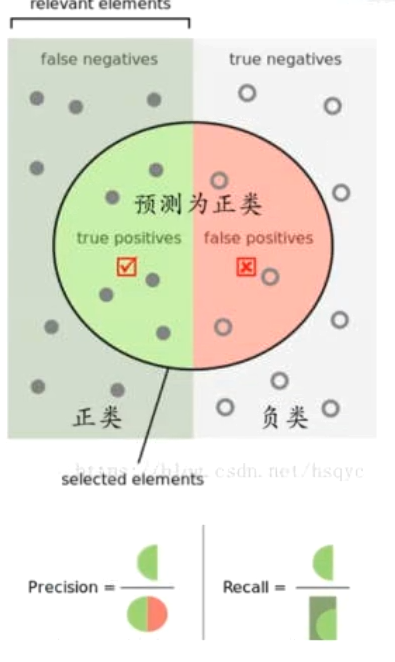
精度/查准率:
预测为正例的样本中实际为正例的比例
召回率/查全率:
实际为正例的样本中被正确预测的比例
mAP
- 划定不同阈值计算不同的精度/召回率
- 计算在不同阈值的情况下,Predicision和Recall的值。
- 阈值0.9:无视所有小于0.9的predict,那么此时TP=1,FP=0,precision=1,所有标签数目为3,那么recall=1/3
- 阈值0.8:无视所有小于0.8的predict,那么此时TP=1,FP=1,precision=1/2,所有标签数目为3,那么recall=1/3
- 阈值0.7:无视所有小于0.7的predict,那么此时TP=2,FP=1,precision=2/3,所有标签数目为3,那么recall=2/3
- 计算在不同阈值的情况下,Predicision和Recall的值。
- 根据精度/召回率,绘制RP曲线,计算AP值
- 在每个”峰值点”往左画一条直线,和上一个“峰值点”的垂直线像交,这样和坐标轴框出来的面积就是AP值。
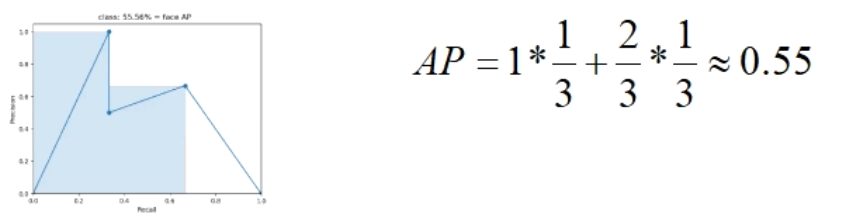
- mAP:对多个类别的检测情况评估
overfeat
时间:2013年
特点:采用了一种基于 滑动窗口 和 全卷积神经网络(FCN) 的方法来实现目标的分类和定位
流程
- 通过FCN全卷积网络提取特征
- 首先定义若干个大小窗口(K个)
- K中每个窗口都要滑动图片,每个窗口都需要滑动M次
- 得到K x M个特征图
- 对每个位置的特征图进行目标分类和定位
- 输出每个窗口的类别得分和边框坐标
NMS
去除冗余的候选框,只保留最具代表性的框,提升检测的准确性
- 标准 NMS
- 经典的 NMS 计算方法,直接移除冗余框
- 对于每个框,按得分降序排列,对所有其他框计算 IOU,并移除重叠框
- Soft NMS
- Soft NMS 不直接去除重叠的框,而是平滑它们的得分。具体来说,随着重叠度增加,框的得分会逐渐衰减(通过一个衰减因子)
- 避免移除可能是正确框的高 IOU 框,尤其是在物体边缘的框
Two-Stage
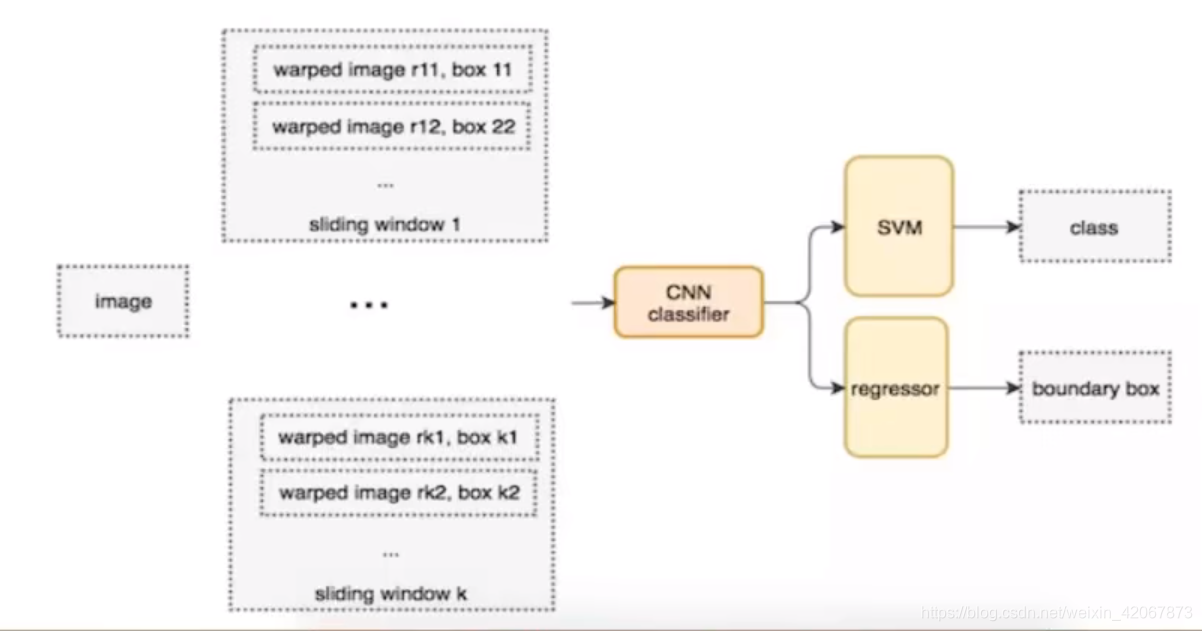
RCNN(Region-based CNN)
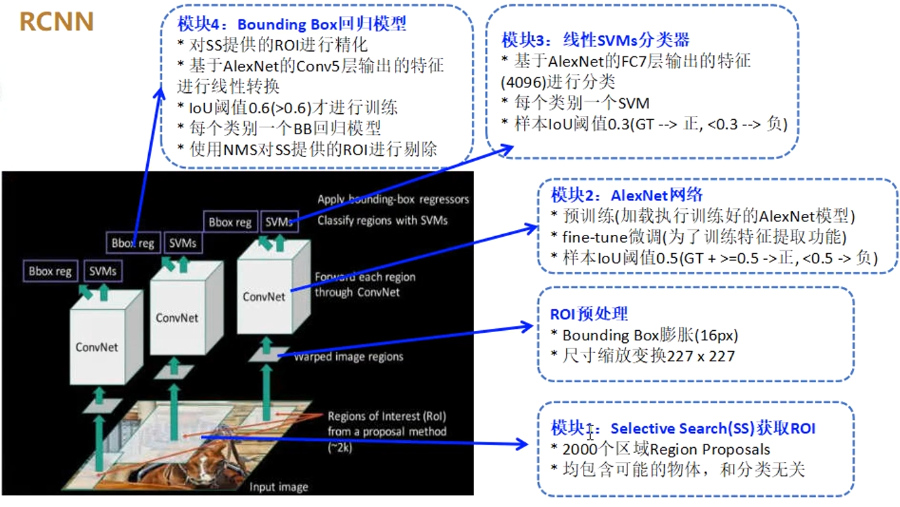
流程
- 生成候选区域:基于颜色、纹理等低级特征合并超像素
- 统一候选区域:将每个候选区域缩放至固定尺寸
- 提取特征:使用预训练的CNN(如AlexNet)提特征
- 分类与回归:使用SVM分类/线性回归修正边界框
SPPNet
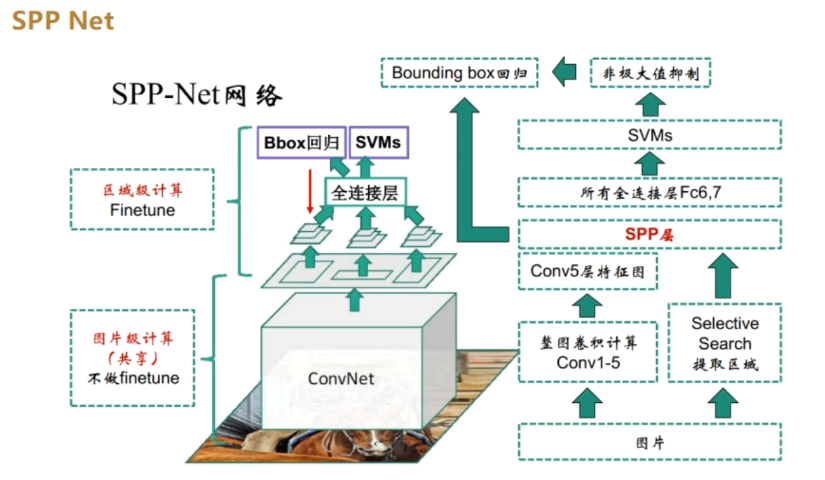
流程
- 整图输入CNN生成特征图。
- 候选区域通过坐标映射到特征图对应位置。
- 使用SPP层(如4级金字塔:1x1、2x2、3x3、6x6)池化
- 分类与回归:使用SVM分类/线性回归修正边界框
Fast RCNN
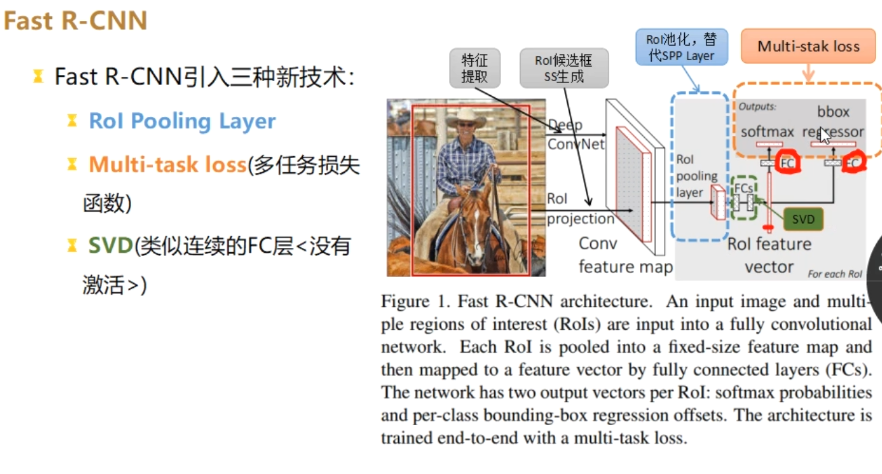
流程
- 整图输入CNN生成特征图
- 用Selective Search(选择性搜索算法)生成候选框(ROIs)
- RoI Pooling将不同尺寸候选框(ROIs)映射到特征图并池化为统一特征图大小
- 两个全连接层分别输出分类结果和边界框偏移量
- 多任务损失训练分类与回归网络
Faster RCNN
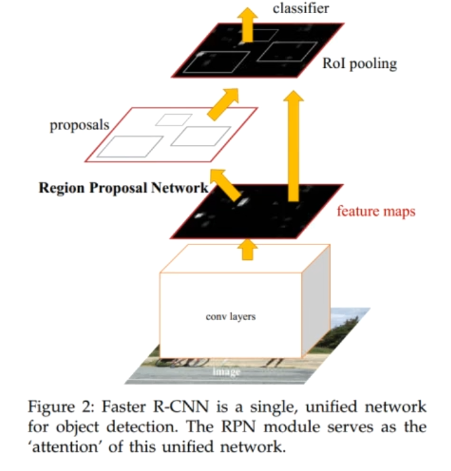
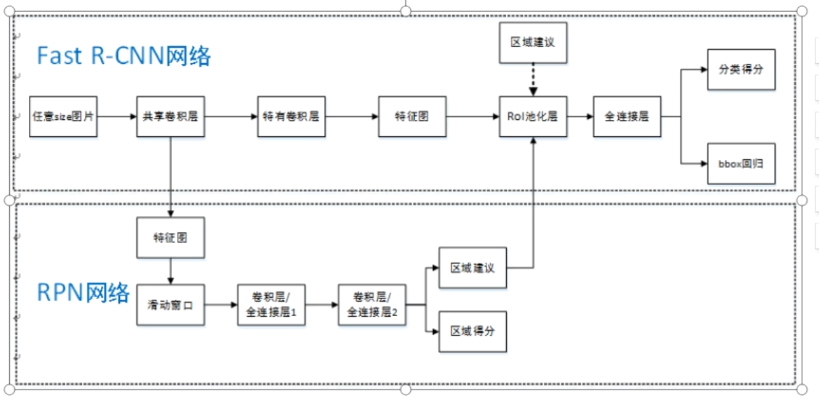
流程
- 整图输入CNN生成特征图。
- RPN生成候选框并过滤(NMS去除低质量候选框 + 高精度低召回率 = 量少质优~300个)
- RoI Pooling将候选框映射到特征图并池化
- 两个全连接层分别输出分类结果和边界框偏移量
- 多任务损失训练分类与回归网络
对比总结
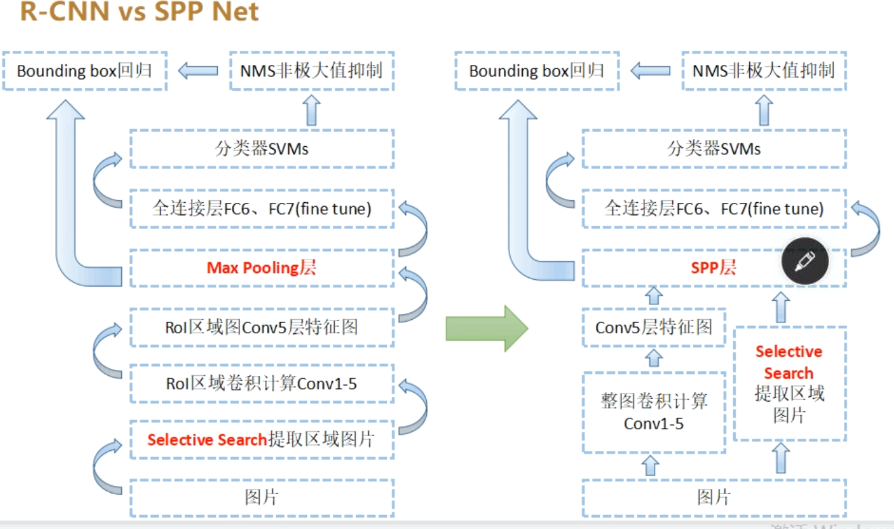
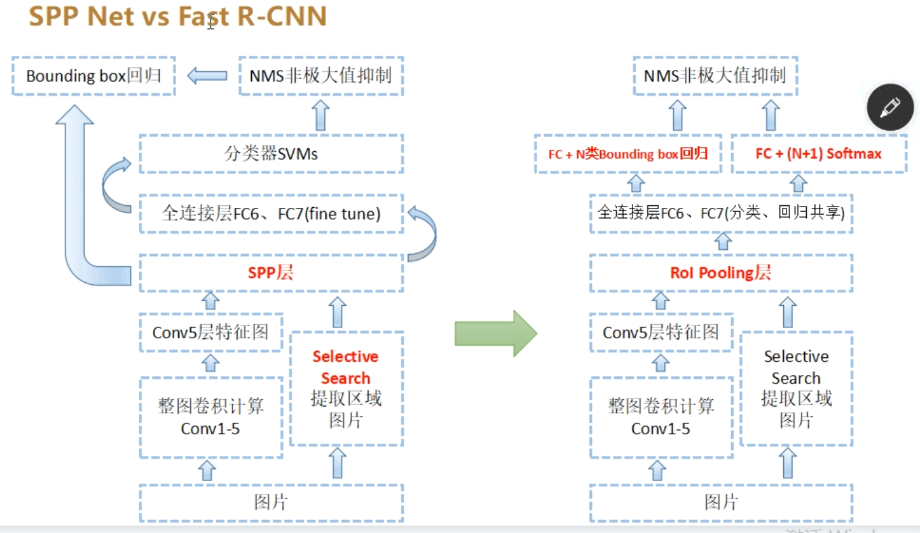
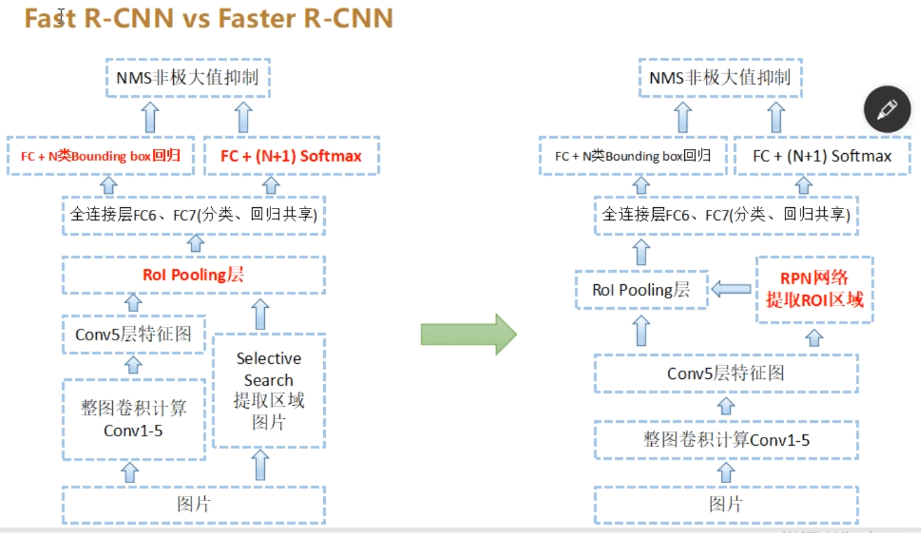
R-CNN网络演进:

RFCN
One-Stage
SSD
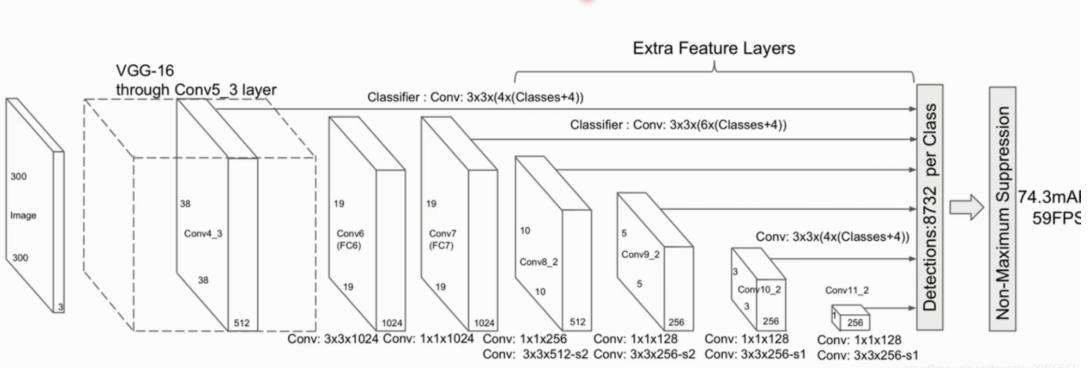
流程
- 整图输入基础网络(如VGG)生成多尺度特征图。
- 每个特征图位置预测K个Anchor的类别和坐标偏移。
- 通过NMS筛选最终检测框。
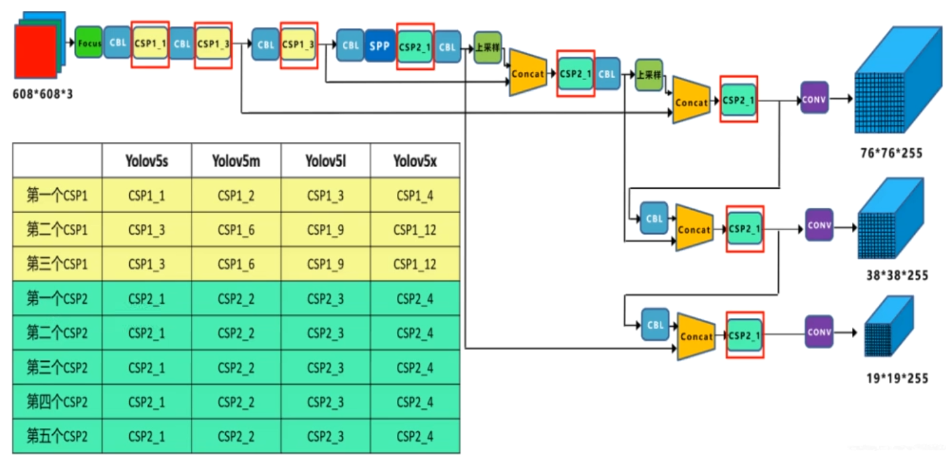
YOLOv1
输入图片:448*448*3
每个小框预测位置信息(x, y, w, h, c)+ 类别概率信息C
- x:coordinate of bbox center inside cell([0;1] wrt grid cell size)
- y:coordinate of bbox center inside cell([0;1] wrt grid cell size)
- w:bbox width ([0;1] wrt image)
- h:bbox width ([0;1] wrt image)
- c:bbox confidence ~ P(obj in bbox1)
- C:C个不同类别概率信息
YOLOv2
YOLOv3
YOLOv4
YOLOv5
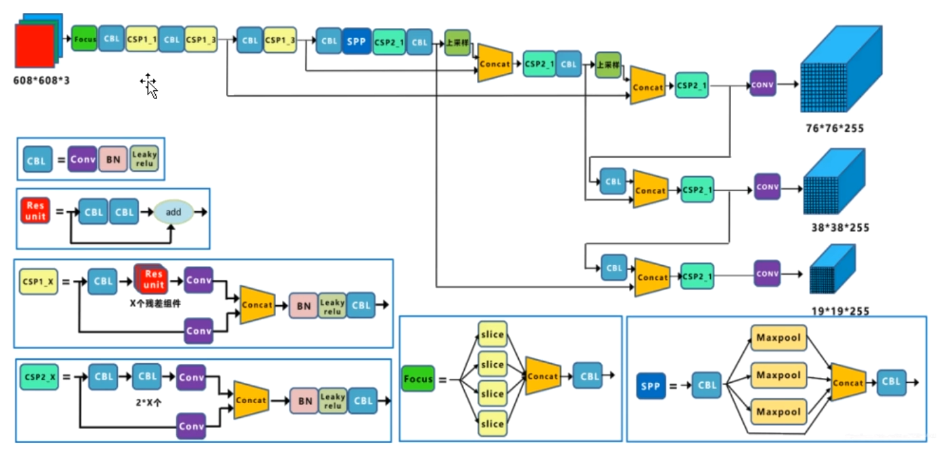

YOLO...
大模型与多模态
概述
基本Pipeline:问题明确->数据获取->数据清理->数据探索->数据准备->训练模型->微调模型->结果应用->监控迭代
整体视角
- 数据决定算法的上线,模型只是去逼近这个上线
- 算法工程师的基础能力:数据采集、评估、传输、预处理、标注、分析、挖掘、特征融合等
LLM构建流程
| 预训练 | 有监督微调 | 奖励建模 | 强化学习 | |
|---|---|---|---|---|
| 数据集合 | 原始数据 [数千亿单词:图书、百科、网页等] | 标注用户指令 [数万用户指令和对应的答案] | 标注对比对 [数万量级标注对比对] | 用户指令 [十万量级用户指令] |
| 算法 | 语言模型训练 | 语言模型训练 | 二分类模型 | 强化学习方法 |
| 模型 | 基础模型 | SFT模型 | RM模型 | RL模型 |
| 资源需求 | 1000+GPU[月] | 1-100GPU[天] | 1-100GPU[天] | 1-100GPU[天] |
有监督微调:
指令微调(Instruction Tuning)利用少量高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务
- 如何微调?利用高质量有监督数据,使用与训练阶段相同的语言模型训练算法,在基础语言模型基础上再训练,得到有监督微调模型(SFT模型)
- 微调后的效果:具备初步指令理解能力和上下文理解能力,能够完成开放领域问题、阅读理解、翻译、生成代码等能力,也具备一定对未知任务的泛化能力
下游任务微调:
DownstreamTaskFine-tuning
目的:在通用语义表示基础上,根据下游任务的特性进行适配
注意:容易使得模型遗忘预训练阶段学习到的通用语义知识表示,损失模型的通用性和泛化能力,造成灾难性遗忘(CatastrophicForgetting)问题,因此通常采用混合预训练任务损失和下游微调损失的方法来缓解
奖励建模:
Reward Modeling
目的:构建一个文本质量对比模型,对于同一个提示词,SFT模型给出的多个不同输出结果的质量进行排序
注意:RM模型的准确率对于强化学习阶段的效果有至关重要的影响,因此需要大规模训练数据
强化学习:
Reinforcement Learning
流程:根据数十万用户给出的提示词,利用在前一阶段训练的RM模型,给出CFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好效果
该阶段使得基础模型的熵降低,会减少模型输出的多样性
- 从数据集中sample一个prompt
- 语言模型(policy)生成输出
- 使用奖励模型(Environment)计算得分(Reward)由使用PPO-ptx算法优化语言模型

LLM参数
采样系数Top-k
如何预测下一个词
在某一解码时间步,固定选取前k个概率对应的词作为候选,并按照概率进行采样
采样并不代表每次都会选概率最大的,只是概率越大被选中的几率越大
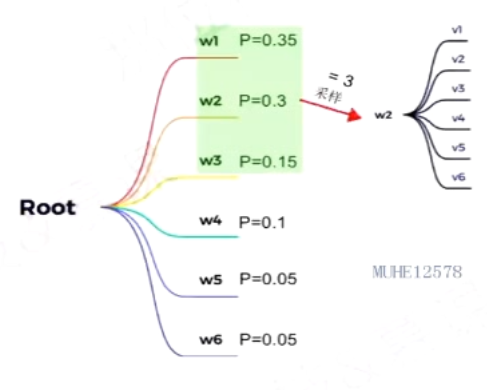
top-k值对解码效果影响:
- k值变大:选择范围变大,输出更加多样化但精确度也会降低
- k值变小:输出更加确定但缺乏多样性
缺点:
- 不会更具词的概率分布动态调整k值
采样系数Top-p
解决了Top-k采样中只能固定选取前k个词的问题
在某一解码时间步,动态选取概率之和大于p的最小集合作为候选,并按照概率进行采样
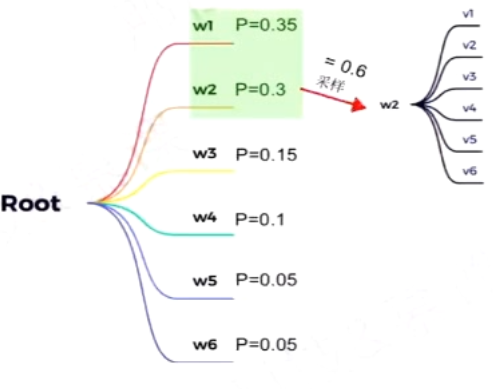
给定p值时,候选词列表的大小主要由概率分布决定:
- 如果模型对下一个词比较确定,则候选词列表会比较小
- 反之,概率分布会相对均匀(对下一个词不确定),此时候选列表会相对大一些
实际应用:
- 将
Top-k和Top-p方法进行结合,先应用Top-k,然后应用Top-p
温度系数Temperature
控制了softmax输出分布,Temperature=1时退化为标准softmax函数

Temperature对输出结果的影响:
- 当Temperature较低时(如0.1/0.2):模型倾向于选择概率较高的单词,生成的文本较为连贯和准确,但可能显得过于保守,缺乏创造性和多样性
- 当Temperature较高时(如0.8/1.0):模型倾向于选择概率较低的单词,生成的文本较为多样和创造,但可能牺牲了一定的连贯性和准确性
应用技巧:
- LLM中普遍取值一般为0.2~1.0
- 对于多样性要求较高的任务(例如对话、文本生成)可适当提高温度系数
预训练模型分类
NLU类
自然语言理解
- 以
BERT为代表的自编码预训练模型,NLU任务:分配、抽取等 - 如何训练?借助特定的预训练任务进行学习,如:掩码语言模型(MLM)、下一个句子预测(NSP)等
- 双向语言模型,同时建模上文和下文信息
- 代表模型:RoBERTa、ALBERT、ELECTRA、DeBERTa等
- NLU任务特点:输出范围确定、评价方法相对明确
NLG类
自然语言生成
- 以
GPT为代表的自回归预训练模型,NLG任务:文本生成、生成式摘要、对话等 - 如何训练?使用Causal LM训练(N-gram语言模型的自然延申),无需设计复杂的预训练任务
- 单向语言模型,部分模型采用双向编码器和单向编码器结构
- 代表模型:GPT系列(Decoder-only)、T5和BART(Encoder-Decoder)等
- NLG任务特点:输出自由度搞、评价方法较难、更具有创造性
模型的涌现能力
《Emergent Abilities of Large Language Models》
基于模型放大
- TruthfulQA:当模型放大至280B,其效果会突然高于随机20%
- Multi-task language understanding:当训练计算量达到70B-280B后效果将远远超过随机
- Word in Context:当PaLM被缩放至540B时,高于随机的效果出现
根据文章:Scaling Laws for Neural Language Models
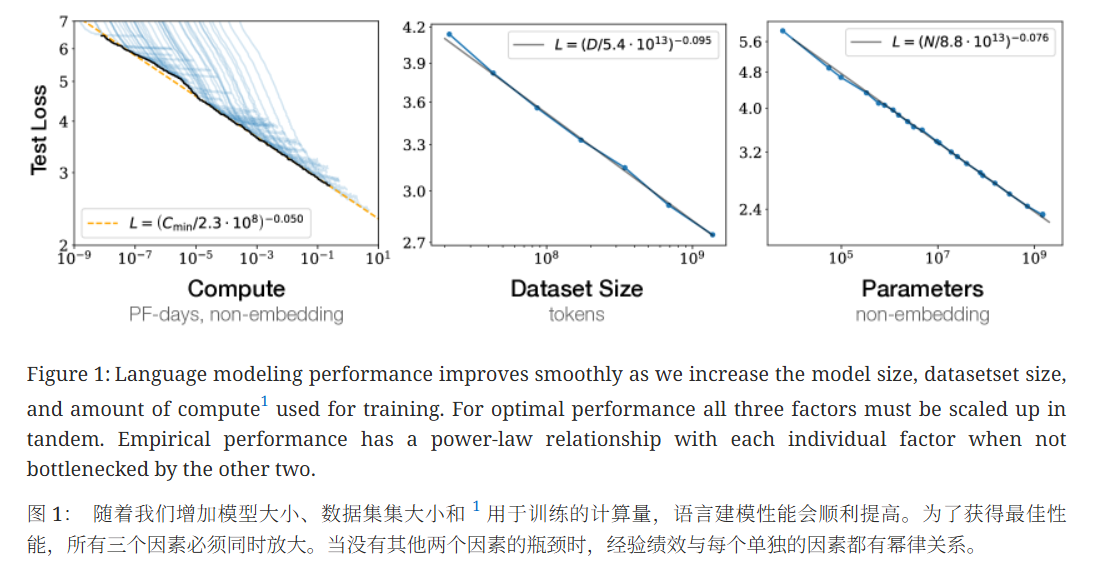
基于样例提示
通过 few-shot prompting来执行任务的能力也是一种涌现现象
transformer

- BERT(Bidirectional Encoder Representations from Transformers):双向语言理解模型,仅使用 编码器,用于理解整个句子的上下文,适合分类、问答等理解类任务。
- GPT(Generative Pre-trained Transformer):自回归语言模型,仅使用 解码器,其设计目的是生成下一个词,适合用于生成式任务,如文本生成、对话等。
多模态
基本结构
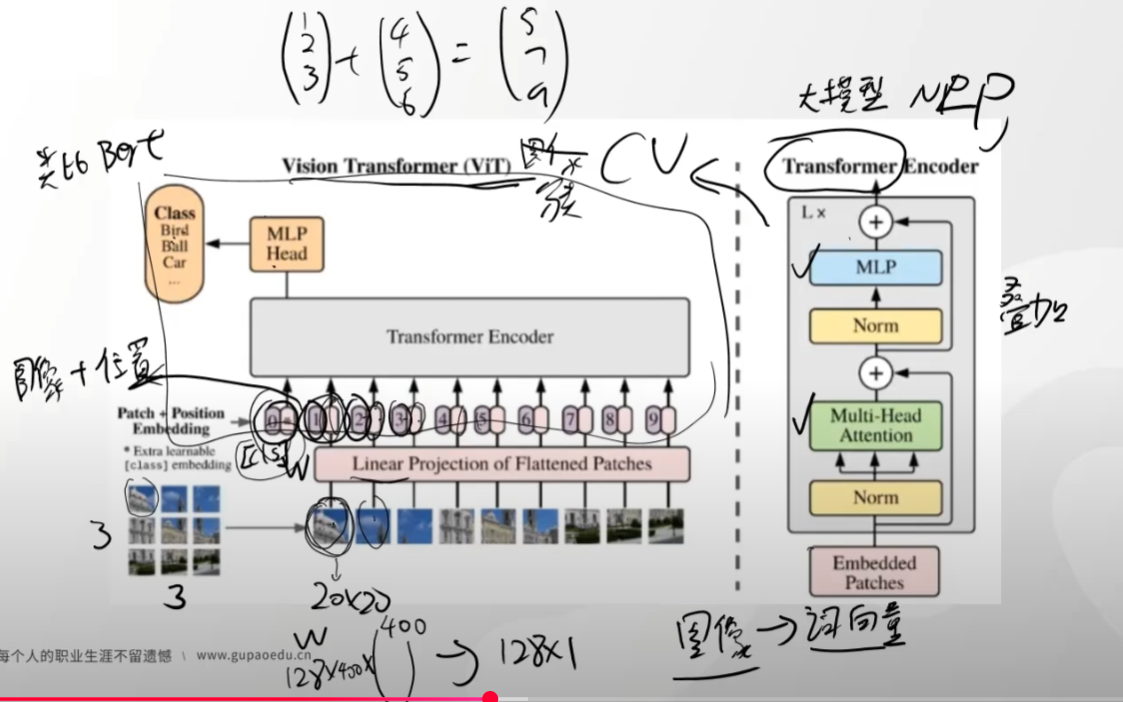
vit
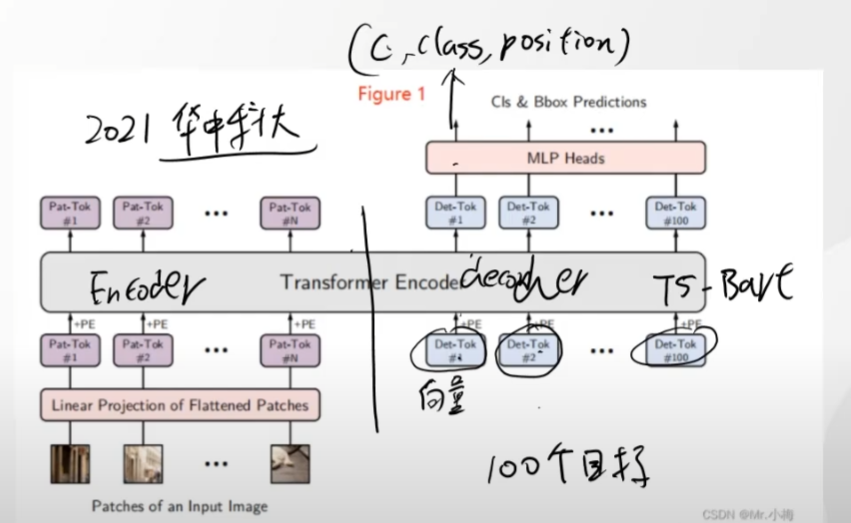
yolos
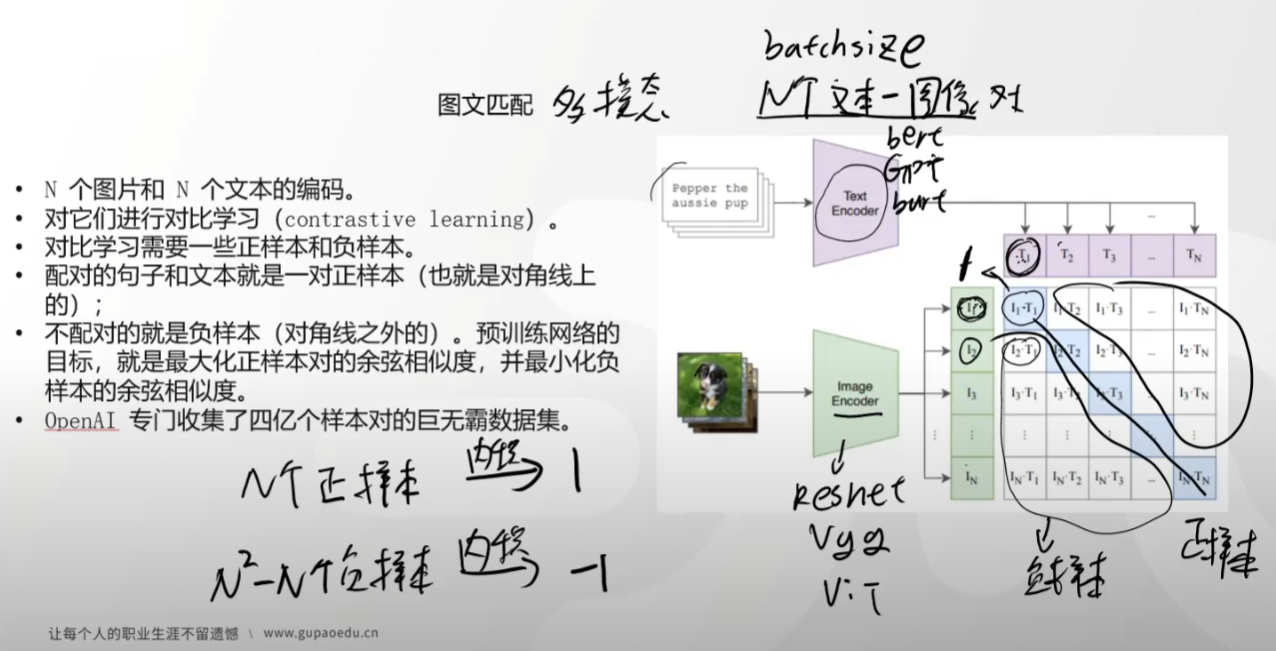
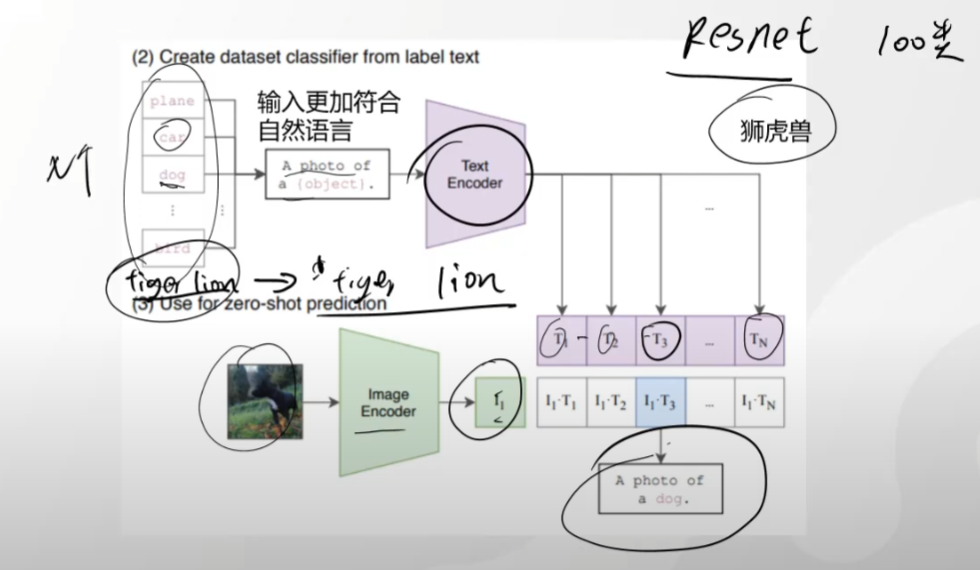
图文匹配
clip

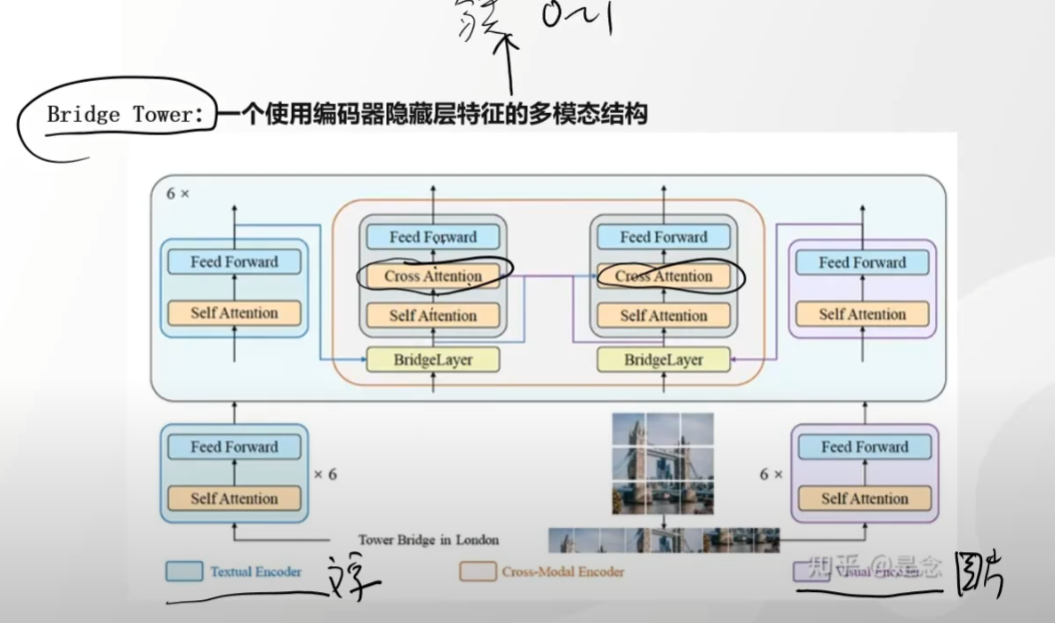
bridge tower

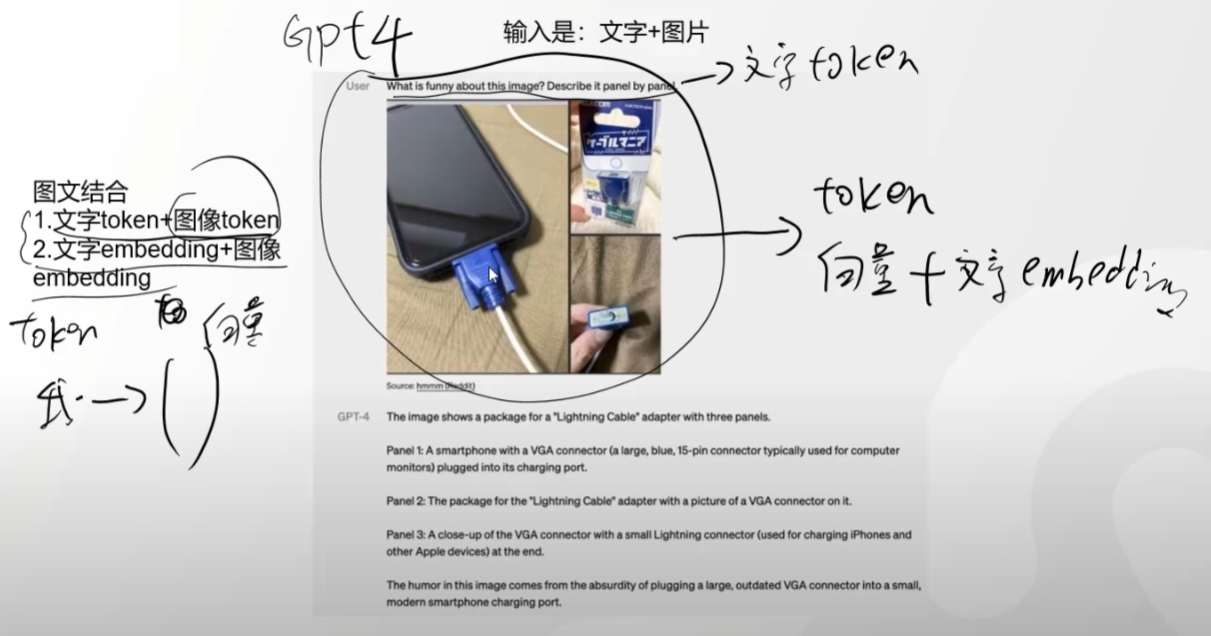
gpt4原理
文生图/图生文
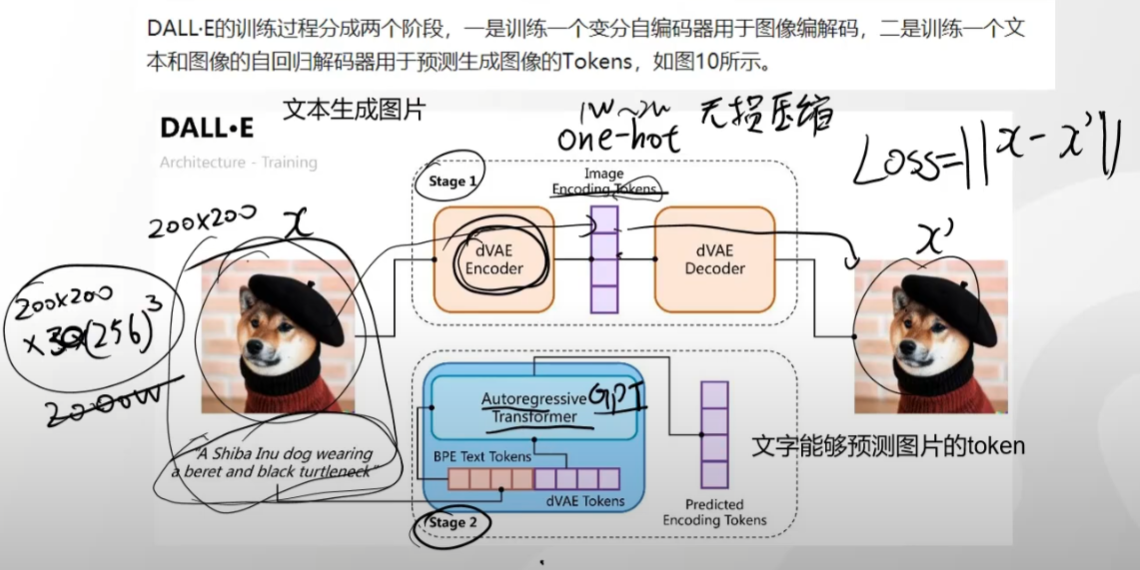
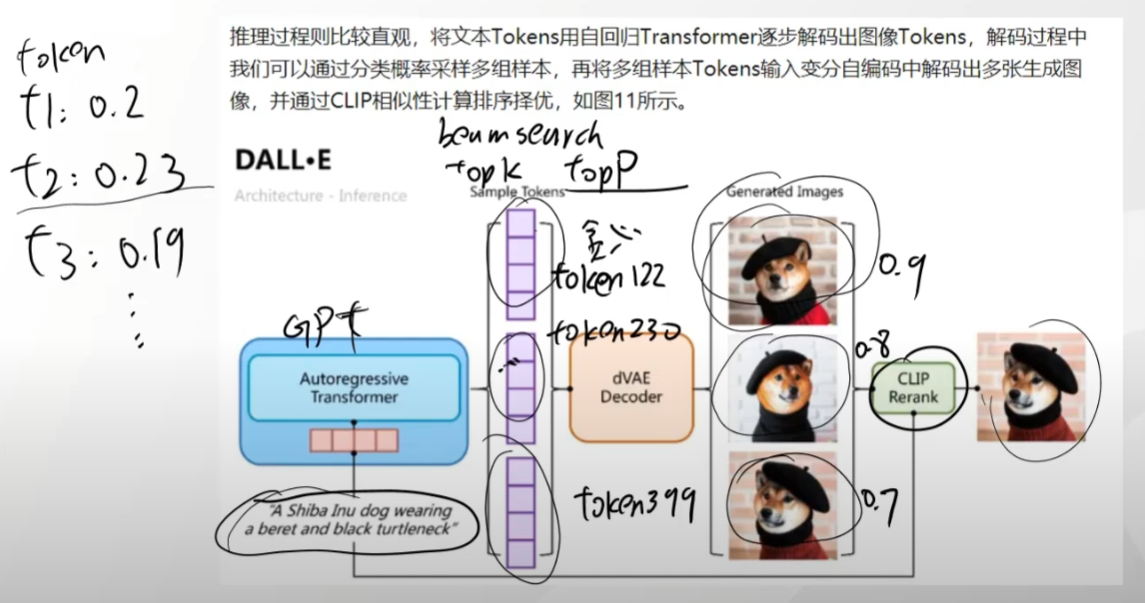
DALL · E
扩散模型
模型微调
处理不当,很可能造成模型原始能力的灾难性以往、即回导致模型原始能力丢失,对于复杂模型更是如此
微调概念
全量微调
- 对所有参数进行微调
- 对算力和显存要求高
- 效果最佳
局部微调
重要调整输入输出层效果明显,而非中间层
- 只调整某些某部分参数,例如输入层,输出层或某些特殊层
- 对算力和显存要求一般
- 一定是有效的
增量微调
前/后增量:
- 改变任务(如:2->8分类),选择后增
- 模型是一个提取特征的过程,后增效果好
- 通过新增参数的方式进行微调,新的知识存储在新的参数中。
- 对显存和算力要求低
- 效果不如全量微调
微调方式
LoRA(Low-Rank Adaption)
通过引入低秩矩阵来减少微调时的参数量。在预训练的模型中,LoRA通过添加两个小矩阵A和B来近似原始的大矩阵,从而减少需要更新的参数数量。
- A和B的秩远小于原始矩阵的秩,从而大大减少了需要更新的参数数量
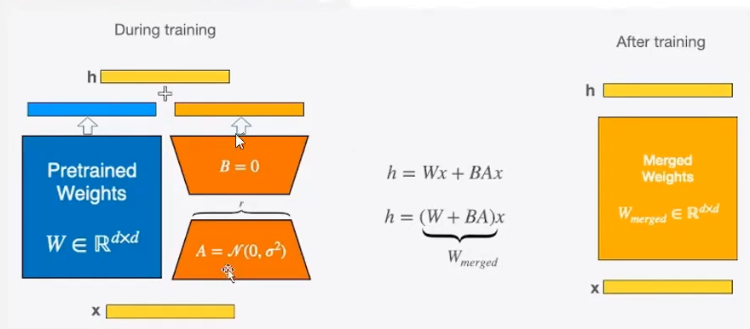
- 训练时:输入分别与原始权重和两个低秩矩阵进行计算,共同的到最终结果,优化则仅优化A和B
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无异
QLoRA
Quantized Low-Rank Adaption,在LoRA的基础上加入量化技术,减少权重表示的位数,从而降低显存和计算需求
- 量化:将模型权重量化为低精度(如INT4),减少内存占用,并提高推理和训练速度
微调工具
Llama-Factory
Xtuner
性能评估:EvalScope
https://evalscope.readthedocs.io/zh-cn/latest/best_practice/qwen3.html#id7
模型部署
Ollama
- 针对个人用户
- 必须是gguf格式的模型【GGUF格式一般是量化后的】
安装
一键安装
curl -fsSL https://ollama.com/install.sh | sh
sudo vim /etc/systemd/system/ollama.service
sudo ufw allow 11434/tcp
sudo systemctl daemon-reload & sudo systemctl restart ollamaollama.service
使用显卡进行推理
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/mnt/big_disk_0/spa/.cargo/bin:/mnt/big_disk_0/spa/miniconda3/bin:/mnt/big_disk_0/spa/miniconda3/condabin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/mnt/big_disk_0/spa/.local/bin:/mnt/big_disk_0/spa/bin"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="CUDA_VISIBLE_DEVICES=1,0"
[Install]
WantedBy=default.target使用
ollama serveollama run 模型:参数BVllm
- 企业专用
- 一次只支持部署一个模型
vllm serve /mnt/big_disk/big_disk_3/spa/Code/Study/llm/XiaomiMiMo/MiMo-7B-RL \
--trust_remote_code \
--tensor-parallel-size 4 \
--served-model-name MiMo-7B-RLLMDeploy
- 显存优化比vllm好点
- 只支持列表内模型
lmdeploy serve api_server internlm/internlm2_5-7b-chat版权所有
版权归属:HuiXiaHeYu