Python
Python3源码文件默认以UTF-8编码,所有字符串都是unicode字符串。
导入库
- 模块=文件夹=包
将整个模块(somemodule)导入:import somemodule
从某个模块中导入某个函数: from somemodule import somefunction
从某个模块中导入多个函数: from somemodule import firstfunc,secondfunc,thirdfunc
将某个模块中的全部函数导入: from somemodule import \*引入自定义模块
from test1 import t1
print(t1.add(3,5))pip的使用
pip介绍
pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。
各版本区别
Python 2.7.9 + 或 Python 3.4+ 以上版本都自带 pip 工具。
pip 官网:https://pypi.org/project/pip/pip 命令
# 判断是否已安装
pip --version # Python2.x 版本命令
pip3 --version # Python3.x 版本命令
# 获取帮助
pip --help
# 升级 pip
pip install --upgrade pip
# 安装指定版本的pip包
pip install SomePackage # 最新版本
pip install SomePackage== # 查看支持版本
pip install SomePackage==1.0.4 # 指定版本
pip install 'SomePackage>=1.0.4' # 最小版本
pip install --upgrade SomePackage # 升级包(可使用==, >=, <=, >, < 来指定一个版本号)
pip uninstall SomePackage # 卸载包
pip search SomePackage # 搜索包
pip show # 显示安装包信息
pip show -f SomePackage # 查看指定包的详细信息
pip list # 列出已安装的包
pip list -o # 查看可升级的包
pip install -e xxx [--use-pep517] # 以可编辑模式安装。--use-pep517表示使用隔离环境(pyproject.toml中 [build-system].requires 指定的依赖)安装本地安装模块方法
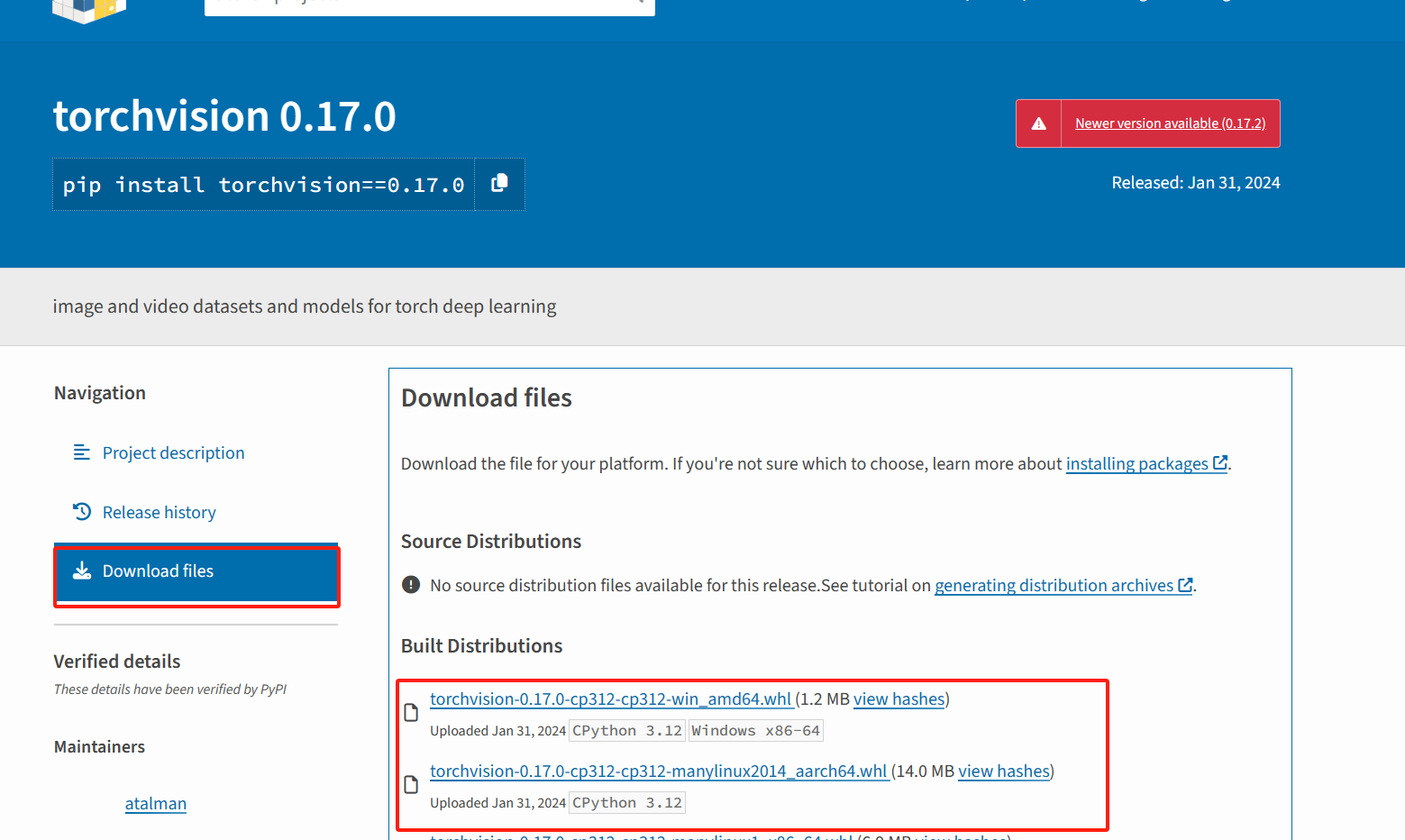
https://pypi.org/
- 打开此网页并搜索到要安装的模块并点击
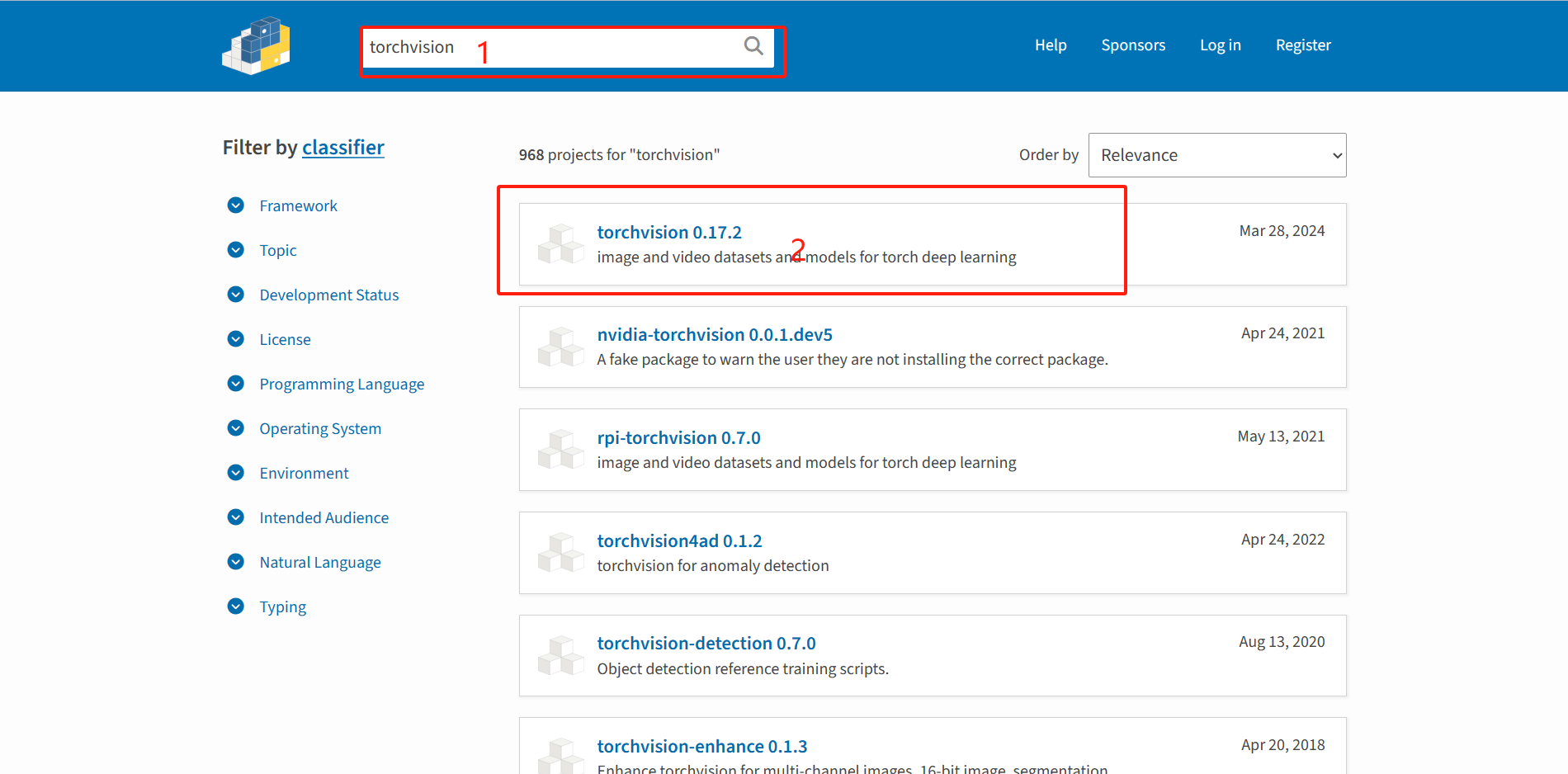
- 点击找到下载文件目录并找到合适的模块版本,之后下载到桌面
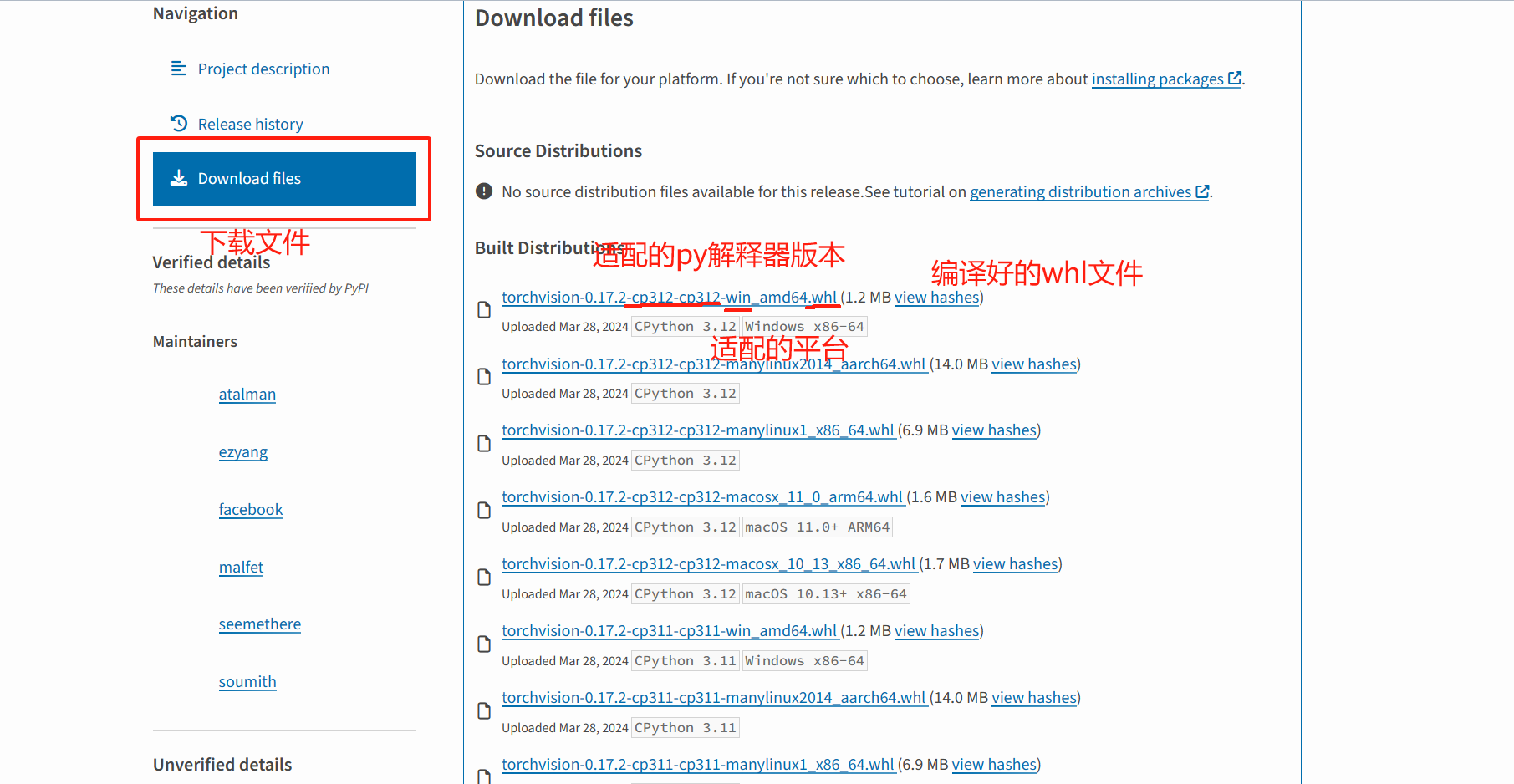
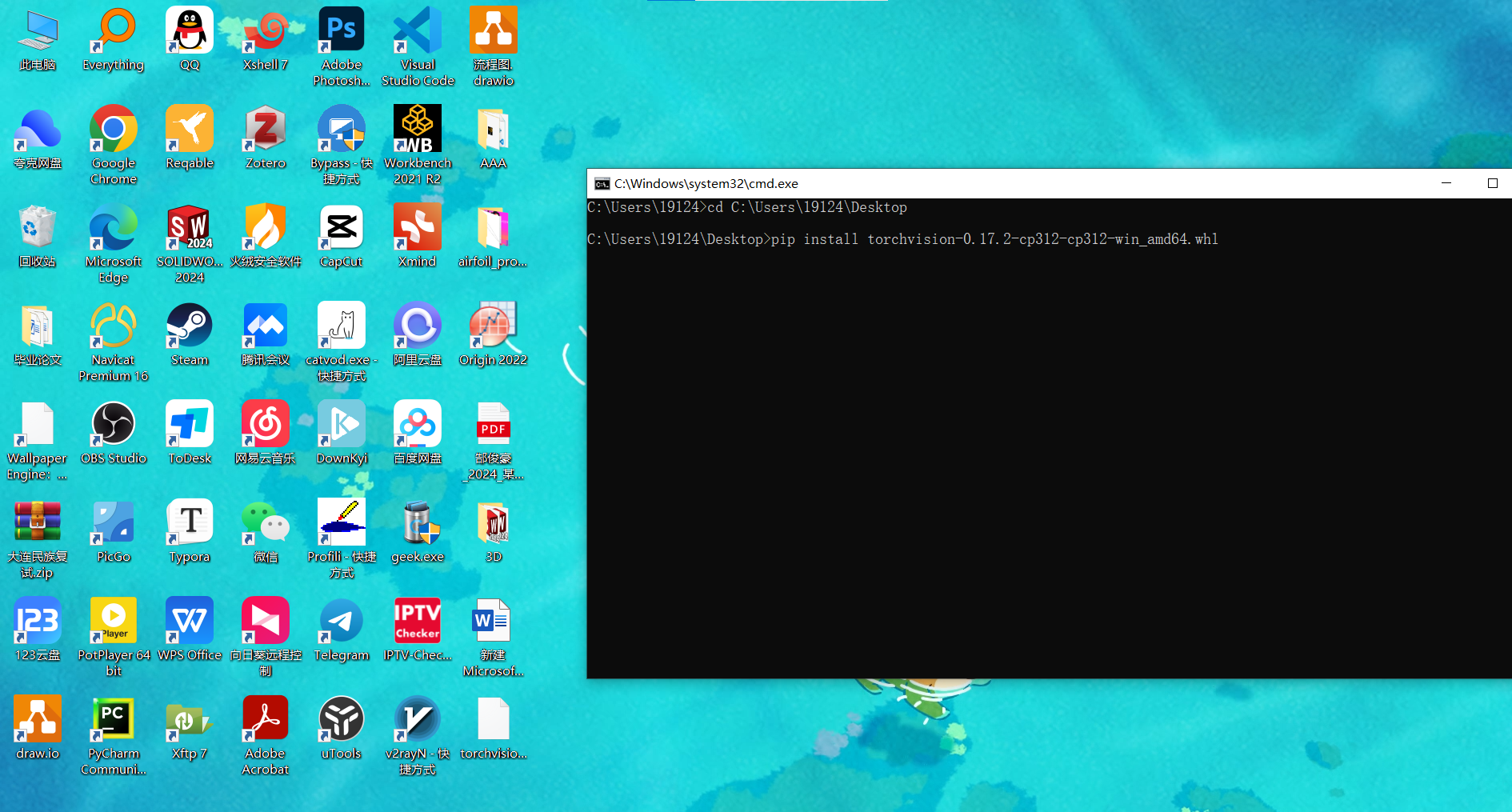
- cmd窗口进入whl文件路径并手动安装
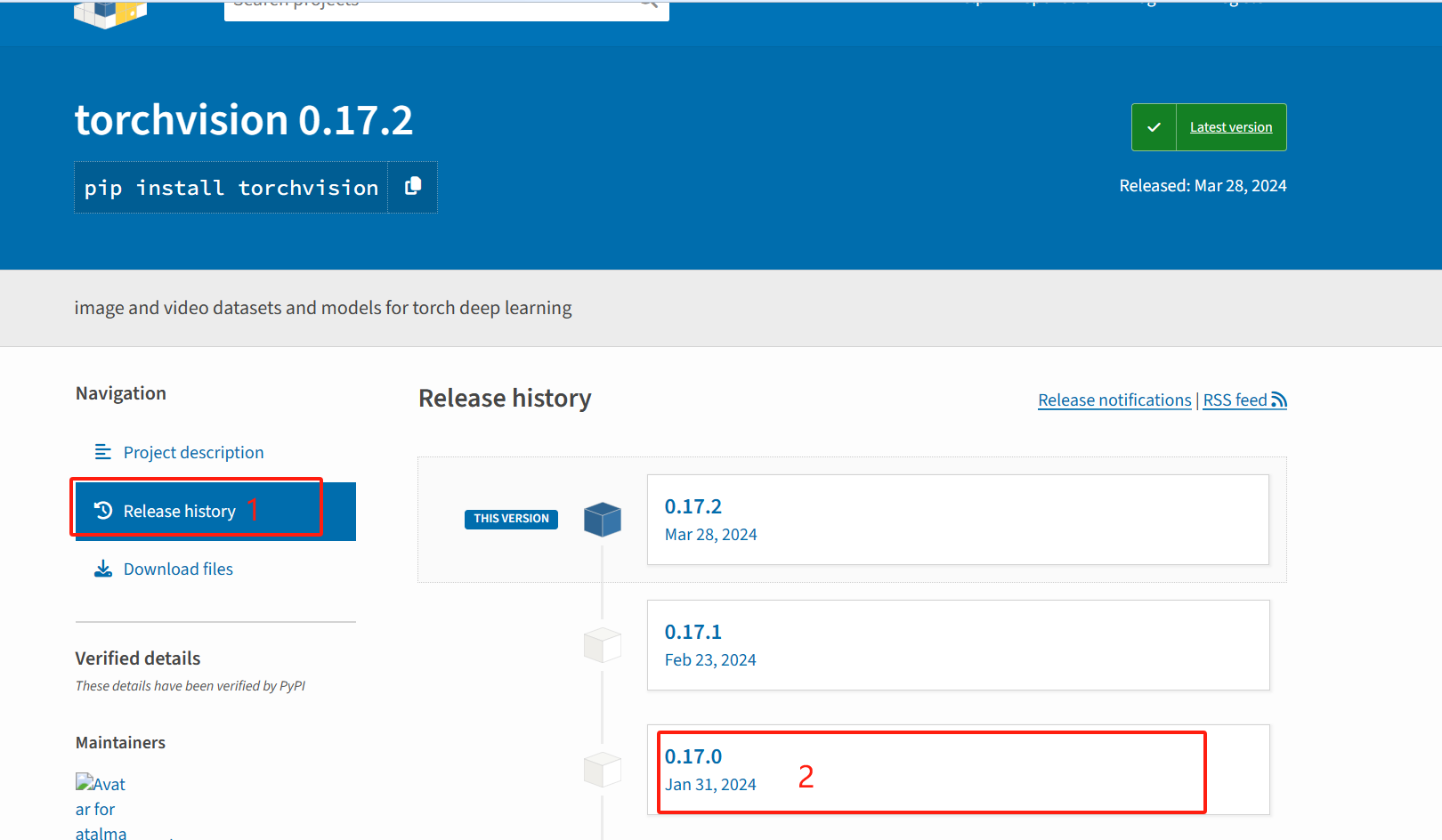
- 也可以查询历史版本并下载
生成依赖文件
pip freeze > requirements.txt各种源
pip源
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
使用方法【以清华源为例】
- 临时使用
pip install some-package -i https://pypi.tuna.tsinghua.edu.cn/simple # 临时使用来下包
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip # 临时使用来升级pip下载器- 设为默认【只允许pip>=10.0.0进行配置】
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip install --upgrade pip
# 官方源
pip config set global.index-url https://pypi.org/simple
conda config --remove-key channelsgithub源
分支源码:https://github.moeyy.xyz/https://github.com/moeyy/project/archive/master.zip
release源码:https://github.moeyy.xyz/https://github.com/moeyy/project/archive/v0.1.0.tar.gz
release文件:https://github.moeyy.xyz/https://github.com/moeyy/project/releases/download/v0.1.0/example.zip
分支文件:https://github.moeyy.xyz/https://github.com/moeyy/project/blob/master/filename
Raw:https://github.moeyy.xyz/https://raw.githubusercontent.com/moeyy/project/archive/master.zip
使用Git: git clone https://github.moeyy.xyz/https://github.com/moeyy/projecthuggingface源
必须加在前两行
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
export HF_ENDPOINT="https://hf-mirror.com"Setuptools更改源
直接在setup.py的同目录放置一个setup.cfg:
[easy_install]
index_url = https://pypi.tuna.tsinghua.edu.cn/simple基本数据类型
赋值:
"""单个变量赋值"""
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串"""多个变量赋值"""
# 法一:
a = b = c = 1
# 法二:
a, b, c = 1, 2, "runoob"number
- 整型:int
- 浮点数类型:float
- 复数类型:complex
string
单引号
双引号
三引号(允许跨行输入)
多次输出
print (str * 2)
print (2 * str)拼接
字符串
print (str + "TEST")变量
f-string形式(Python 3.6及以上版本)【最直观、易读、性能最好】:
pythonname = "Alice" age = 25 message = f"My name is {name} and I am {age} years old." print(message)在字符串前加上 'f' 的语法,然后在字符串中使用花括号
{}插入变量。%格式化字符串形式【老的代码】:pythonname = "Bob" age = 30 message = "My name is %s and I am %d years old." % (name, age) print(message)%s表示字符串格式,%d表示整数格式,然后在字符串末尾使用%运算符和元组进行格式化。逗号加变量形式【打印到控制台常用】:
变量自动以空格连接在一起pythonname = "Charlie" age = 22 print("My name is", name, "and I am", age, "years old.")
bool
int类型的子类
- True:所有
非零的数字和非空的字符串、列表、元组等 - False:
0、空字符串、空列表、空元组等
list【可变、有序】
- 列表中元素的类型可以不相同,支持:数字、字符串、列表(嵌套)
创建
my_list = [] # 创建一个空列表
my_list = [1,2]添加
"""
单个元素
"""
my_list.append(10) # 末尾添加
my_list.insert(idx,element) # 指定位置插入"""
多元素列表
"""
# 末尾添加整体列表
my_list.append(my_list1)
# 末尾添加拆散列表
my_list.extend(my_list1)删除
del语句【通用的删除方式,根据索引删除元素 或 删除整个列表】:功能:
del语句用于删除列表中指定索引位置的元素或删除整个列表。语法:
del list_name[index]或del list_name。示例:
pythonmy_list = [10, 20, 30, 40, 50] del my_list[2] # 删除索引为2的元素(值为30) # 输出: [10, 20, 40, 50] print(my_list) del my_list # 删除整个列表 # NameError: name 'my_list' is not defined(此时my_list已不存在)
remove方法【根据值删除第一个匹配的元素】:功能:
remove方法用于根据值删除列表中的元素,仅删除第一个匹配的元素。语法:
list_name.remove(value)。示例:
pythonmy_list = [10, 20, 30, 20, 40, 50] my_list.remove(20) # 删除值为20的元素(仅删除第一个匹配的元素) # 输出: [10, 30, 20, 40, 50] print(my_list)
pop方法【删除指定索引位置的元素,返回该元素的值】:功能:
pop方法用于删除指定索引位置的元素,并返回该元素的值。语法:
list_name.pop(index)。示例:
pythonmy_list = [10, 20, 30, 40, 50] popped_element = my_list.pop(2) # 删除索引为2的元素(值为30)并返回该值 # 输出: 30 print(popped_element) # 输出: [10, 20, 40, 50] print(my_list)
tuple【不可变、有序】
创建
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号添加
创建一个新的元组,包含原有元组的内容以及要添加的新元素。
my_tuple = (1, 2, 3) # 原始元组
element = 4 # 要添加的新元素
# 创建一个新的元组,包含原始元组的内容以及新元素
new_tuple = my_tuple + (element,)
# 输出: (1, 2, 3, 4)
print(new_tuple)删除
创建一个新的元组,排除你想要删除的元素。
my_tuple = (1, 2, 3, 4, 5) # 原始元组
# 创建一个新的元组,排除值为2的元素
new_tuple = tuple(x for x in my_tuple if x != 2)
# 输出: (1, 3, 4, 5)
print(new_tuple)dictionary【键值对】
子类:
.keys():所有键
.values():所有值
.items():所有键值对
.get(key):获取指定键对应的值
创建
my_dict = {} # 创建空字典
my_dict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}添加
如果键不存在,则添加新元素;如果键已经存在,则更新对应的值。
pythonmy_dict = {'a': 1, 'b': 2, 'c': 3} # 原始字典
# 添加新元素或更新已存在的元素
my_dict['d'] = 4
# 输出: {'a': 1, 'b': 2, 'c': 3, 'd': 4}
print(my_dict)删除
del方法【通用的删除方式,根据指定键删除键值对】:
pythonmy_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4} # 原始字典
# 使用 del 语句删除指定键的元素
del my_dict['b']
# 输出: {'a': 1, 'c': 3, 'd': 4}
print(my_dict)pop()方法【删除指定键的键值对,返回该键的值】:
pythonmy_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4} # 原始字典
# 使用 pop() 方法删除指定键的元素,并返回其值
popped_value = my_dict.pop('b')
# 输出: 2
print(popped_value)
# 输出: {'a': 1, 'c': 3, 'd': 4}
print(my_dict)set【无序、元素唯一】
创建
注意:{}用来创建一个空字典。
my_set = set()添加
add()方法【添加单个元素】:
pythonmy_set = {1, 2, 3} # 原始集合
# 使用 add() 方法添加单个元素
my_set.add(4)
# 输出: {1, 2, 3, 4}
print(my_set)update()方法【添加多个元素】:
pythonmy_set = {1, 2, 3} # 原始集合
# 使用 update() 方法添加多个元素
my_set.update({3, 4, 5})
# 输出: {1, 2, 3, 4, 5}
print(my_set)删除
- 使用
remove()方法【要删除的元素不存在,会引发 KeyError】:
pythonmy_set = {1, 2, 3, 4, 5} # 原始集合
# 使用 remove() 方法删除指定元素
my_set.remove(3)
# 输出: {1, 2, 4, 5}
print(my_set)- 使用
discard()方法【要删除的元素不存在,不会引发 KeyError】:
pythonmy_set = {1, 2, 3, 4, 5} # 原始集合
# 使用 discard() 方法删除指定元素
my_set.discard(3)
# 输出: {1, 2, 4, 5}
print(my_set)集合运算
- 并集
pythonset1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1.union(set2)
# 输出: {1, 2, 3, 4, 5}
print(union_set)- 交集
pythonset1 = {1, 2, 3}
set2 = {3, 4, 5}
intersection_set = set1.intersection(set2)
# 输出: {3}
print(intersection_set)- 差集:返回包含在第一个集合中但不在第二个集合中的元素的新集合。
pythonset1 = {1, 2, 3}
set2 = {3, 4, 5}
difference_set = set1.difference(set2)
# 输出: {1, 2}
print(difference_set)- 对称差集/异或集:返回包含两个集合中所有不重复元素的新集合(即,去除两个集合的交集)。
pythonset1 = {1, 2, 3}
set2 = {3, 4, 5}
symmetric_difference_set = set1.symmetric_difference(set2)
# 输出: {1, 2, 4, 5}
print(symmetric_difference_set)- 使用运算符进行运算。
# | 表示并集
# & 表示交集
# - 表示差集
# ^ 表示对称差集
pythonset1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1 | set2 # 并集
intersection_set = set1 & set2 # 交集
difference_set = set1 - set2 # 差集
symmetric_difference_set = set1 ^ set2 # 对称差集
# 输出: {1, 2, 3, 4, 5}
print(union_set)
# 输出: {3}
print(intersection_set)
# 输出: {1, 2}
print(difference_set)
# 输出: {1, 2, 4, 5}
print(symmetric_difference_set)Bytes类型(以b开头的字符串)
重点与str类型进行区分:
- str类型(字符串)【Unicode编码存储】是以字符为单位进行处理的。
- bytes类型【二进制数据的编码格式决定存储方式】是以字节为单位处理的。
b = b'' # 创建一个空的bytes
b = byte() # 创建一个空的bytes
b = b'hello' # 直接指定这个hello是bytes类型
b = bytes('string') #利用内置bytes方法,将字符串转换为默认utf-8的bytes
b = bytes('string',encoding='编码类型') #利用内置bytes方法,将字符串转换为指定编码的bytes
# 省事写法
byte1 = str.encode('编码类型') # 将str编码成bytes,默认为utf-8进行编码。
str1 = bytes.decode('编码类型') # 将bytes解码成str,默认使用utf-8进行解码。切片
语法
- 变量[下标]
- 变量[开始向后:开始向前]
- 变量[开始向后:开始向前:步进值]
"""字符串切片"""
str = 'Runoob'
print (str) # 输出字符串
print (str[0:-1]) # 输出第一个到倒数第二个的所有字符"""列表切片"""
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
print (list) # 输出完整列表
print (list[0]) # 输出列表第一个元素
print (list[1:3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素类型提示
| 类型 | 用途 |
|---|---|
int | 整数 |
float | 浮点数 |
str | 字符串 |
bool | 布尔值 |
List[T] | 列表,包含元素类型 T |
Tuple[T1, T2] | 元组,包含特定类型的元素 |
Dict[K, V] | 字典,键类型为 K,值类型为 V |
Set[T] | 集合,包含元素类型 T |
Union[T1, T2] | 联合类型,可以是 T1 或 T2 |
Optional[T] | 可以是 T 类型,也可以是 None |
Callable | 表示函数或可调用对象 |
Any | 任意类型 |
Literal | 字面量类型 |
运算符
算术操作符
在混合计算时,Python会把整型转换成为浮点数。
+ # 加
- # 减
* # 乘
/ # 除 返回浮点数
% # 取模(取整)
// # 整除 返回整数 例子:9//2为4,-9//2为-5
** # 幂 例子:9**2为81成员运算符
in # 如果在指定的序列中找到值返回True,否则返回False
not in # 如果在指定的序列中==没有找到==值返回Tue,否则返回False身份运算符
| 运算符 | 描述 | 例子【例子中的id(X)函数用于获取对象内存地址】 |
|---|---|---|
| is | is是判断两个标识符是不是引用自一个对象 | x is y,类似id(x)==id(y),如果引用的是同一个对象则返回Tue,否则返回False |
| is not | is not是判断两个标识符是不是引用自不同对象 | x is not y,类似id(a)!=id(b)。如果引用的不是同一个对象则返回结果True,否则返回False |
比较运算符(类似C语言,不再赘述)
不再赘述赋值运算符(类似C语言,不再赘述)
**= # 幂赋值运算符 类似C语言
//= # 取整除赋值运算符 类似C语言位运算符(类似C语言,不再赘述)
& # 按位与:各二进制位与:1&0为0,1&1为1,0&0为1
| # 按位或:各二进制位或:(例:1001|0011为1011)
^ # 按位异或:各二进制位异或(相异结果为1):(例:1001^0011为1010)
~ # 按位取反:各二进制位取反:(例:~1为0)
<< # 左移运算符:【高位丢弃,低位补0】各二进制位左移
>> # 右移运算符:各二进制位左移逻辑运算符(类似C语言,形式改动)
与 或 非
and or not条件判断和循环语句
条件判断
if 判断条件1:
第一个执行语句
elif 判断条件2:
第二个执行语句
else:
第三个执行语句循环
for循环
- 遍历数字
【i为从0到结束数的每一个数字】
for i in range(结束数): print(i)【i为从起始数到结束数的,以步进数为步进的每一个数字】
for i in range(起始数,结束数,步进数): # 左闭右开 print(i)
遍历字符串【i为字符串中从前到后的每一个字符】
for i in "asidojaodw": print(i)遍历列表【i为列表中从前到后的每一个元素】
正常遍历
fruits = ['banana', 'apple', 'mango'] for i in fruit: print(i)通过数组下标遍历(其实就是列表)
fruits = ['banana', 'apple', 'mango'] for index in range(len(fruits)): print ('当前水果 : %s' % fruits[index])通过枚举类型遍历
fruits = ['banana', 'apple', 'mango'] for i, fruit in enumerate(fruits): print('下标:%d\t当前水果 : %s' % (i, fruit))
同时迭代多个对象
# 以字典为例 my_dict = {'a': 1, 'b': 2, 'c': 3} for key, value in my_dict.items(): print(key, value)循环判断
for i in range(结束数): 执行语句 else: 不符合条件的执行语句
while循环
while 判断语句:
执行语句
else:
不符合条件的执行语句break、continue、pass
- break:跳出(终止)循环
- continue:跳过本次循环
- pass:占位符,空语句
函数
语法
def example(positional, keyword=None, *args, **kwargs):
"""
keyword=None 默认参数:在函数定义时为参数提供默认值,如果调用时未传递该参数,则使用默认值。
"""
print(f"Positional: {positional}") # 位置参数:最常见的参数类型,按位置传递给函数。
print(f"Keyword: {keyword}") # 关键字参数:通过参数名传递给函数,顺序无关紧要。
print(f"Args: {args}") # 可变位置参数:使用 *args 语法,允许传递任意数量的位置参数,参数在函数内部会被收集成一个元组。
print(f"Kwargs: {kwargs}") # 可变关键字参数:使用 **kwargs 语法,允许传递任意数量的关键字参数,参数在函数内部会被收集成一个字典。
# 调用示例
example(1, keyword=2, 3, 4, a=5, b=6)类与对象
方法
# 1.实例方法:第一个参数是 self; 实例方法可以访问和修改实例的属性。
class MyClass:
def instance_method(self):
return f"Instance method called on {self}"
obj = MyClass()
print(obj.instance_method()) # 输出: Instance method called on <__main__.MyClass object at 0x...>
# 2.类方法:@classmethod 装饰器定义; 第一个参数是 cls,表示类本身; 类方法可以访问和修改类的属性。
class MyClass:
class_attribute = "class attribute"
@classmethod
def class_method(cls):
return f"Class method called on {cls}, class attribute: {cls.class_attribute}"
print(MyClass.class_method()) # 输出: Class method called on <class '__main__.MyClass'>, class attribute: class attribute
# 3.静态方法:@staticmethod 装饰器定义; 无法访问或修改类或实例的状态,通常用于一些独立的功能。
class MyClass:
@staticmethod
def static_method():
return "Static method called"
print(MyClass.static_method()) # 输出: Static method called继承
class parent_cl: # 父类
def __init__(self, name):
self.name = name
def get_params(self):
return self.name
class sub_cl(parent_cl): # 子类
def __init__:
super().__init__()
pass
a = sub_cl("xvyang")
print(a.get_params())文件操作
file函数
open( )
语法
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode参数
特性解析(可混用)
- “+”:读写
- “b”:二进制格式打开
| 模式 | 阐述 |
|---|---|
| r【只读】 | 指针在开头(默认模式)。 |
| w【写入】 | 写入字符串(resp.text) 文件存在 => 覆盖; 文件不存在 => 创建新文件。 |
| a【追加】 | 指针在末尾。 文件存在 => 追加; 文件不存在 => 创建新文件。 |
举个栗子:
| 模式 | 阐述 |
|---|---|
| rb【只读】 | 二进制格式,指针在开头。 |
| wb【写入】 | 二进制格式写入字节(resp.content)。 |
| ab【追加】 | 二进制格式,指针在结尾。 |
| r+【读写】 | 指针在开头。 |
| w+【读写】 | |
| a+【读写】 | 指针在结尾。 |
| rb+【读写】 | 二进制格式,指针在开头。 |
| wb+【读写】 | 二进制格式。 |
| ab+【追加读写】 | 二进制格式,指针在末尾。 |
file.close( )
关闭文件。关闭后文件不能再进行读写操作。
file.read( )
读取指定的字符,开始时定位在文件头部,每执行一次向后移动指定字符数
file.readline( )
读取整行,包括 "\n" 字符
file.readlines( )
读取所有行并返回列表(若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区)。
其他file函数:
[Python3 File 方法 | 菜鸟教程 (runoob.com)](https://www.runoob.com/python3/python3-file-methods.html)
文件的相关操作【OS模块】
文件重命名
import os
os.rename("毕业论文.txt","毕业论文-最终版.txt")删除文件
import os
os.rename("毕业论文.txt")创建文件夹
如果存在此文件夹,则抛出异常
import os
os.mkdir("张三")获取当前目录
import os
os.getcwd()改变默认目录
import os
os.chdir("../")获取目录列表
import os
os.listdir("./")删除文件夹
import os
os.rmdir("张三")异常捕获
语法

try:
pass # 代码
except Exception as e:
print(f"报错了,报错原因:{e}")这里的报错原因很重要
抛出异常
使用rasie来抛出一个指定的异常
例子:
>>> try:
raise NameError('HiThere') # 模拟一个异常。
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere抛出自定义异常
- 继承自 Exception 类,直接继承或间接继承,
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = messagewith语句:预定义的清理行为
- 封装了 try…except…finally 编码范式,用于异常处理【更加易用】。
with open('./test_runoob.txt', 'w') as my_file:
my_file.write('hello world!')异常种类
| 名称 | 阐述 |
|---|---|
| ArithmeticError | 所有数值计算错误的基类 |
| ImportError | 导入失败 |
| LookupError | 无效数据查询的基类 |
| NameError | 未声明、初始化对象 |
| OSError | 操作系统错误 |
| RuntimeError | 一般的运行时错误 |
| SyntaxError | Python语法错误 |
| ValueError | 传入无效的参数 |
| Warning | 警告的基类 |
| Exception | 所有错误类型 |
推导式
语法:结果一 if 判断条件 else 结果二 for 变量名 in 原列表
列表(list)推导式
# 例子:过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母: names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] new_names = [name.upper() for name in names if len(name)>3] # new_names为['ALICE', 'JERRY', 'WENDY', 'SMITH']字典(dict)推导式
# 例子:提供三个数字,以三个数字为键,三个数字的平方为值来创建字典: dic = {x: x**2 for x in (2, 4, 6)} # dic为{2: 4, 4: 16, 6: 36}集合(set)推导式
# 例子:判断不是 abc 的字母并输出: a = {x for x in 'abracadabra' if x not in 'abc'} # a为{'d', 'r'}元组(tuple)推导式【返回的是一个生成器对象。】
# 例子:生成一个包含数字 1~9 的元组: a = (x for x in range(1,10)) # a为(1, 2, 3, 4, 5, 6, 7, 8, 9)
Pycharm配置
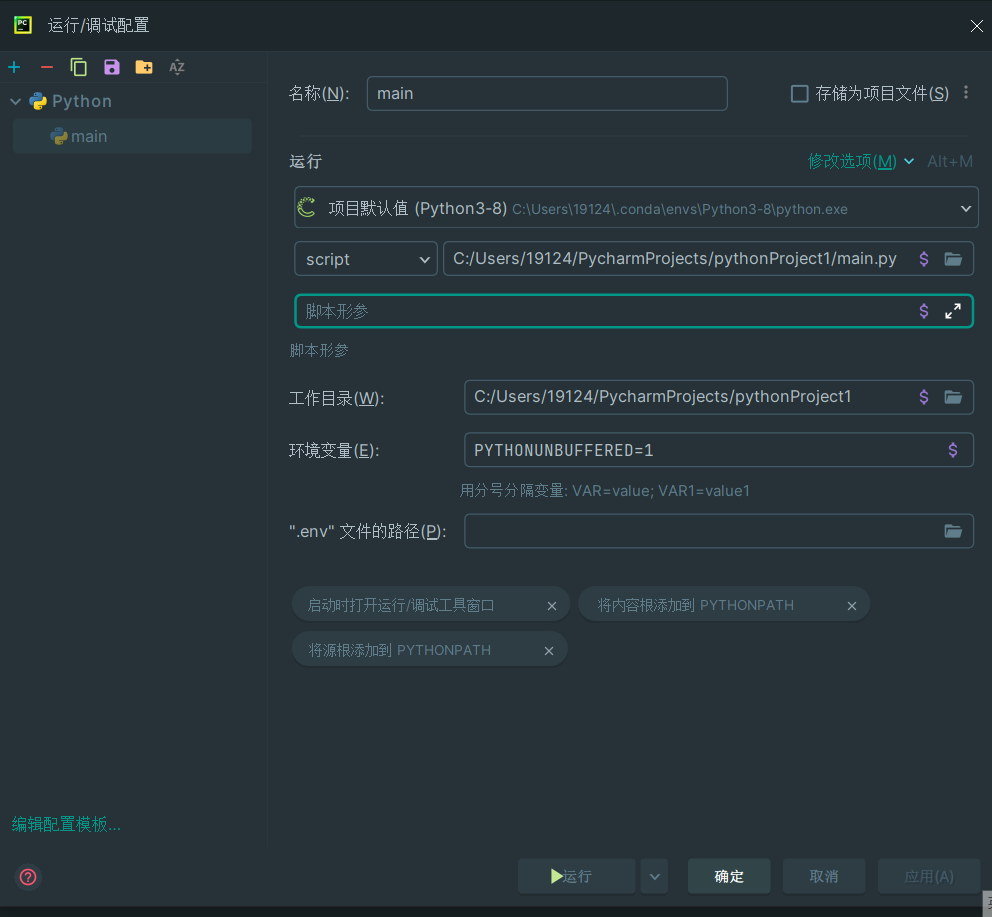
修改脚本形参(全局)
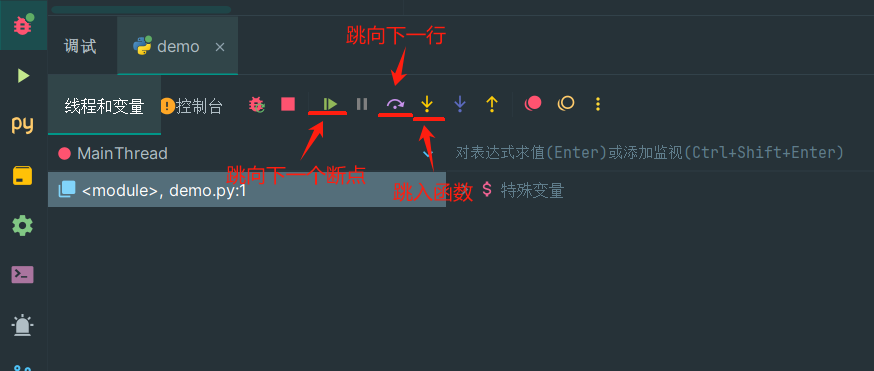
Debug功能
查看函数
笔记本
代码加密和解密执行-base64为例
origin_code = """
My Code
"""
origin_code_bytes = origin_code.encode("utf-8") # 以utf-8:字符串编码为字节
encrypt_code_bytes = base64.b64encode(origin_code_bytes) # base64加密/解密【参数为字节类型】
encrypt_code = encrypt_code_bytes.decode("utf-8") # 以utf-8:字节解码为为字符串
print(encrypt_code)encrypt_code = """
Code
"""
exec(base64.b64decode(encrypt_code.encode("utf-8")))例子:文件批量重命名
import os
import re
directory_path = r"E:\BaiduNetdiskDownload\大明王朝1566"
for filename in os.listdir(directory_path):
full_path = os.path.join(directory_path, filename) # 用于获取文件的完整路径
match = re.search(r'\bEP(\d+)\b', filename)
if match:
episode_number = match.group(1) # 获取匹配到的数字部分
new_filename = f"{episode_number}.mp4" # 使用匹配到的数字部分构造新文件名
print(f"老文件名: {filename}, 新文件名: {new_filename}")
# 如果你确定要重命名文件,可以取消下一行的注释
os.rename(full_path, os.path.join(directory_path, new_filename))例子:利用列表翻转字符串
def reverseWords(input):
# 通过空格将字符串分隔符,把各个单词分隔为列表
inputWords = input.split(" ")
# 翻转字符串
# 假设列表 list = [1,2,3,4],
# list[0]=1, list[1]=2 ,而 -1 表示最后一个元素 list[-1]=4 ( 与 list[3]=4 一样)
# inputWords[-1::-1] 有三个参数
# 第一个参数 -1 表示最后一个元素
# 第二个参数为空,表示移动到列表末尾
# 第三个参数为步长,-1 表示逆向
inputWords=inputWords[-1::-1]
# 重新组合字符串
output = ' '.join(inputWords)
return output
if __name__ == "__main__":
input = 'I like runoob'
rw = reverseWords(input)
print(rw)例子:集合找唯一字符
a = set('abracadabra')
b = set('alacazam')
print(a)例子:格式打印

products = [["iphone", 6888], ["MacPro", 14800], ["小米6", 2499], ["Coffee", 31], ["Book", 60], ["Nike", 699]]
print("-" * 5 + "商品列表" + "-" * 5)
i = 0
for product in products:
print("%s\t%s\t%d" % (i, product[0], product[1]))
i += 1
list1 = []
while True:
i = input("想买什么?")
if i != "q":
list1.append(products[int(i)][0])
else:
for temp in list1:
print(f"{temp}\t")
break例子:古诗写文件及粘贴
def write1():
f = open("gushi.txt", "w")
f.write("\
击壤歌\n\
佚名〔先秦〕\n\
日出而作,日入而息。\n\
凿井而饮,耕田而食。\n\
帝力于我何有哉!")
f.close()
def read_wirte():
try:
f2 = open("copy.txt", "w")
f1 = open("gushi.txt", "r")
try:
f2.write(f1.read())
print("复制完毕")
finally:
f1.close()
f2.close()
except Exception as result:
print(result)
write1()
read_wirte()其他
格式化字符
依赖安装/编译失败
- 如果是pip错误的,直接用conda安装后再使用pip讲其他依赖更新即可
conda install -c conda-forge pycocotools==2.0.6
pip install -r requirements.txt转义字符
类似C语言,不再赘述
- \:可作为续行符
- 字符串前加r:原始字符串(去除转义字符的性质)
>>> print(r'Ru\noob')
Ru\noob==注意:==向一个索引位置赋值,比如 word[0] = 'm' 会导致错误。
显式/隐式类型转换
显式
ord() # 取字符的ascii码值;
chr() # 取ascii码值对应的字符
hex() # 取ascii码值对应的十六进制字符串
oct() # 取ascii码值对应的八进制字符串
int() # 转整数
float() # 转浮点数
complex() # 转复数
str() # 转字符串
tuple() # 转元组
list() # 转列表
set() # 转可变集合 frozenset() # 转不可变集合
dict() # 创建字典
repr() # 转表达式字符串
eval() # 计算在字符串中的有效Python表达式,并返回一个对象隐式
自动将一种数据类型转换为另一种数据类型
# 例子:
# 较低数据类型(整数)就会转换为较高数据类型(浮点数)以避免数据丢失。
num_int = 123
num_flo = 1.23
num_new = num_int + num_flo合并路径、链接
import os
path1 = 'SRCNN'
path2 = 'experiments'
path3 = 'VDSR'
full_path = os.path.join(path1, path2, path3)from urllib.parse import urljoin, urlparse
base_url = 'http://www.example.com/path1/folder1/'
relative_url = 'path2/folder2/page.html'
full_url = urljoin(base_url, relative_url)关于print的使用
# 打印单个变量
print("当前字母: " ,variable)
print("当前字母:%s"%variable)
# 打印多个变量:
print("当前字母: %s 第二个字母:%d" %(variable1,variable2)) # 以%s格式输出variable1和以%s格式输出variable2变量
# 打印字符串的结束符
print("你好",end="") # 表示将字符串"你好"的结束值变为空,拓展:end="\n" end="\t" end="abc"运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数(最高优先级) |
| * / % // | 乘 除 取模 取整除 |
| + - | 加法减法 |
| >> << | 右移 左移 |
| & | 位'AND' |
| ^ | | 比较运算符 |
| <= < > >= | 等于运算符 |
| < > == != | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| and or not | 逻辑运算符 |
局部变量和全局变量【类似C语言,不再赘述】
局部变量变全局变量:加global
# 在函数中修改全局变量
a = 100
def test1():
global a
# 生命全同变量在通数中的标识有
print("test1----修2改前:a=%d" % a)
a = 200
print("test1-----修2改后:a=%d" % a)
def test2():
print("test2---a=%d" % a) # 没有局局部变量,默认使用全局变量
test1()
test2()异常捕获中的局部变量问题
import time
try:
f = open("123.txt", "r")
try:
while True:
content = f.readline()
if len(content) == 0:
break
time.sleep(2)
print(content)
finally:
f.close()
print("文件关闭")
except Exception as result:
print("发生异常。。。")高级方法
yield
帮助函数的返回值为生成器模式
# 生成器
generator = (i for i in range(1,20))
next(generator) # 多次执行,返回不同的值
# yield用法:函数 + 生成器
def generator():
for i in range(3):
yield i
generator = generator()
next(generator) # 多次执行,返回不同的值lambda(匿名函数)
add = lambda x, y: x+y # 定义函数addmap函数
map(function, iterable)
原理
将指定函数应用到可迭代对象的每个元素
return map对象
实例
list(map(lambda x:x+x**2,[2,3,4,5,6]))sort函数
.sort()
原理
"""
params:
reverse:默认降序(False)
key:对每个元素执行函数,依据返回的值对列表进行排序
"""实例
# 字符串长度降序排序
["apple", "banana", "cherry", "date"].sort(key=len, reverse=True)
# 求平方并进行降序排序
[1,2,3,4].sort(key=lambda x: x**2, reverse=True)枚举类型
mylist = ["a", "b", "c", "d"]
for i, x in enumerate(mylist):
print(i + 1, x)执行字符串
eval() # 执行单行字符串代码
exec() # 执行多行字符串代码方法调用与内存
object.方法名:就地操作resp = 方法名(object):不对自身应用,应有返回值
变量与指针
变量是一个指向有类型的对象的指针,变量本身无任何类型。
point = 5 # point是一个指针,而不是类型
point = 10 # 这里是新生成一个int类型的对象point,再让指针point指向它,然后5被丢弃(point的值)装饰器
import time
# 这是一个计算时间的装饰器
def calculate_time(func):
def wrapper(*args, **kwargs): # 创建包装函数
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f"{func.__name__} ran in {end - start} seconds")
return result
return wrapper
@calculate_time
def add(a,b):
return a + b
print(add(5,5))安装其他库环境应对方法
pip install ** --index-url pytorch官方
使用VPN下载whl文件后本地安装
conda install * -c conda-forge
直接安装
python setup.py build develop
执行报错的两个原因:
- 系统cuda版本不对,无法进行合理编译【切换到合适的cuda】
- 依赖管理处理出错【使用
pip install -e .进行处理】
版权所有
版权归属:HuiXiaHeYu